Abstract
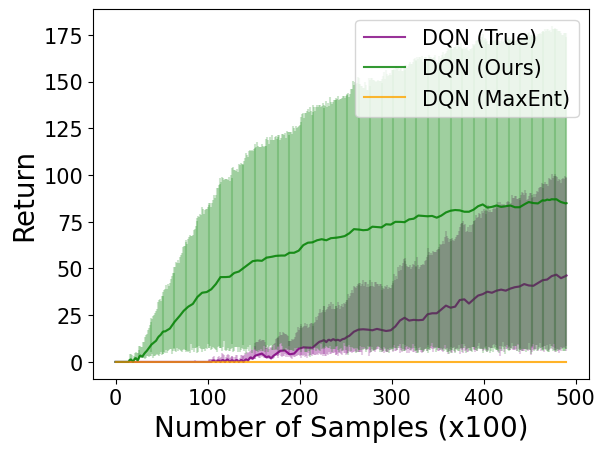
Inverse reinforcement learning (IRL) is computationally challenging, with common approaches requiring the solution of multiple reinforcement learning (RL) sub-problems. This work motivates the use of potential-based reward shaping to reduce the computational burden of each RL sub-problem. This work serves as a proof-of-concept and we hope will inspire future developments towards computationally efficient IRL.
Type
Publication
Accepted at ICLR 2024 as a Tiny Paper (oral presentation)